import pandas as pd
import numpy as np
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.utils import resample11 Validação Cruzada
Imports
Segue abaixo o código da importação dos módulos que usaremos nesse caderno:
Validação Cruzada
Como exposto no caderno de criação e avaliação de preditores, existem diversos métodos de aprendizado de máquina que podemos usar para construir um preditor. Então como saber qual método é melhor? Quais parâmetros usar? Um jeito de resolver essas questões é usando a validação cruzada.
A Validação Cruzada nos permite comparar diferentes métodos de aprendizado de máquina ou parâmetros e avaliar qual funcionará melhor na prática.
Então o que vamos fazer é, para cada método,
- Separar os dados em conjunto de treino e conjunto de teste.
- Treinar um modelo no conjunto de treino.
- Avaliar no conjunto de teste.
- Repetir os passos 1-3 e estimar o erro.
Já sabemos que não é uma boa ideia usar toda a base de dados para treinar o nosso preditor e então podemos dividir por exemplo os primeiros 75% dos dados para treino e 25% finais para teste. Mas, e se esse não for o melhor jeito de dividir nossos dados? E se o melhor jeito de fazer essa divisão for usando os primeiros 25% para teste e o restante para treino? A Validação cruzada leva em consideração todas essas divisões usando uma de cada vez e tirando a média dos resultados no final. Para isso veremos como realizar alguns métodos de reamostragem, para utilizarmos várias amostras possíveis e não ficarmos dependentes de uma única amostra.
Utilizaremos a base Spam ao longo do caderno.
# trocar essa url pelo caminho da base spam de vocês.
Spam = pd.read_csv("Cadernos Grupo Python\\Validação Cruzada\\spam.csv")
# Separando o rótulo das demais variáveis
XSpam = Spam.loc[:, Spam.columns != "type"]
YSpam = Spam["type"]Alguns Métodos de Reamostragem
FALAR SOBRE PORQUE FAZER REAMOSTRAGEM E O QUE ELA É DE FATO
Falaremos de 3 métodos de reamostragem: K-fold, Repeated K-fold e Bootstrap. Daremos uma definição e exemplo de código de cada um para depois entrar em como utilizar na validação cruzada.
K-fold
Definição
Este método consiste em fatiar os dados em k pedaços iguais. Utilizamos um pedaço para o teste e os demais para o treino. Então realizamos esse procedimento k vezes, de modo que em cada repetição um novo pedaço seja utilizado para o teste. Para avaliar o erro nós tiramos a média de todos os erros de todas as replicações.
Exemplo: K-fold com 10 partes:
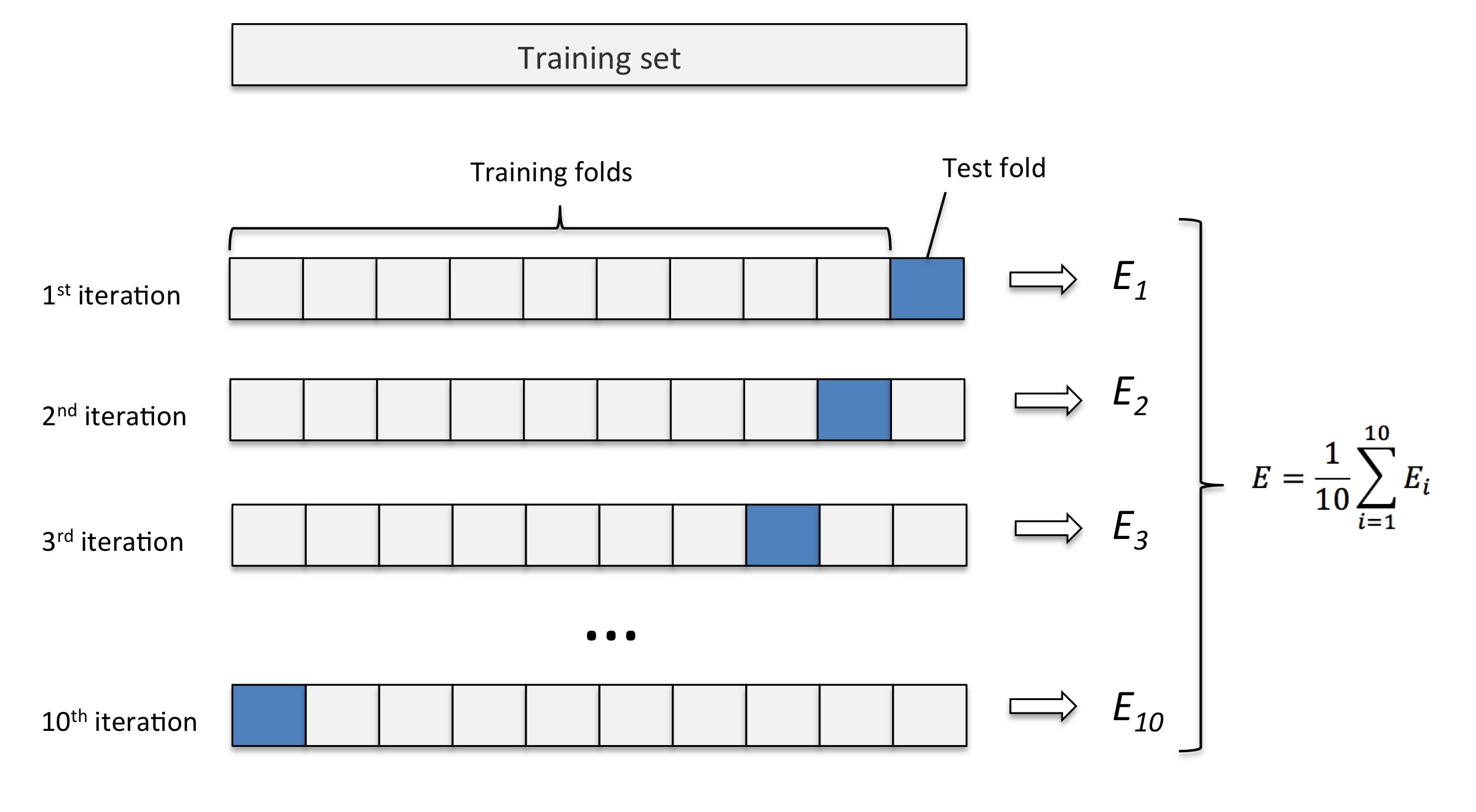
Quanto maior o k escolhido obtemos menos viés, porém mais variância. Em outras palavras, você terá uma estimativa muito precisa do viés entre os valores previstos e os valores verdadeiros, porém altamente variável. Agora quanto menor o k escolhido, mais viés e menos variância. Ou seja, não iremos necessariamente obter uma boa estimativa do viés, mas ela será menos variável.
OBS: Quando o k é igual ao tamanho da amostra, o método é também conhecido como leave-one-out.
Código de exemplo
Vamos utilizar reamostragem por k-fold no conjunto de dados spam usando a implementação do scikit-learn. O scikit-learn possui algumas diferentes implementações para a reamostragem por k-folds. Usaremos a função StratifiedKFold porque ela faz a separação de k-folds preservando a proporção original da coluna com os rótulos.
# Criação dos k-folds
kfSpam = StratifiedKFold(n_splits=10, shuffle=True, random_state=11).split(XSpam, YSpam)Parâmetros da função StratifiedKFold():
n_splits: Recebe o número de partições, o padrão é 5.shuffle: SeFalseos dados seguirão a ordem em que aparecem no conjunto de dados, seTrueos dados serão embaralhados. Padrão éFalse.random_state: Semente de aleatoriedade para o embaralhamento. Padrão éNone.
Logo após chamar a função StratifiedKFold() chamamos um método, .split(). Esse método é aplicado em cima do resultado do StratifiedKFold(). Ele recebe os dados da base utilizada e o rótulo para realizar a separação em k-folds. Fizemos a chamada do método desse jeito para encurtar o processo de separação em k-folds, não usaremos o resultado da função StratifiedKFold() para nada sem antes inserir os dados, assim também evitamos ter uma variável interemediária desnecessária.
O resultado da função StratifeidKFold(), assim como qualquer outra implementação de k-folds no scikit-learn é um generator:
# Tipo da variável resultado do StratifiedKFold().split()
print(type(kfSpam))<class 'generator'>Eles são um tipo especial de vetor, possuindo um comportamento diferente de uma lista, notavelmente ele só pode ser iterado uma vez que para o scikit-learn é o ideal em termos de eficiência computacional. Vamos criar uma lista a partir desse generator apenas para poder entender como o scikit-learn fez a divisão, mas usaremos sempre a variável gerada a partir da chamada do método .split() em cima do resultado da função StratifiedKFold().
# criação de uma lista para reutilização do generator
kfSpamLista = list(kfSpam)
# Exibindo cada k-fold
for K, (train, test) in enumerate(kfSpamLista, 1):
print("K:", K)
print("Treino:", train)
print("Teste:", test)
print(f"len(train): {len(train)}\nlen(test): {len(test)}\n\n")
if K == 3:
breakK, train e test são gerada a partir de kfSpamLista através da função enumerate, um jeito de lidar com a lista gerada a partir do gerador, e são prontamente iterados. O foco dessa explicação é entender como os k-folds funcionam, entender o enumerate e o generator é secundário, não iremos abordar isso futaramente porque são detalhes muito específicos do python que não é importante para entender validação cruzada.
Restringi para exibir apenas 3 k-folds para ficar melhor formatado aqui no caderno. Caso seja do interesse de vocês visualizar o exemplo com todos os k-folds, apenas retire a condição if K == 3: e o break do loop.
No computador de vocês poderá aparecer mais elementos nas listas, formatei para mostrar os 3 primeiros e os 3 últimos apenas para fim explicativo.
Analisando o resultado inteiro com todos os k-folds chegamos a algumas observações importantes:
- a lista treino e teste de cada fold são complementares
- a união entre lista treino e teste de cada fold tem como resultado os índices da base original.
- índices na lista de teste não se repetem em outras listas de teste
- todos os índices passam uma vez pelo conjunto teste de um k-fold
- os índices para treino se repetem K-1 vezes em diferentes folds
REVISAR QUANDO USAR O NOME K-FOLD OU FOLD
REVISAR E POR NOMENCLATURA VARIAVEL RESPOSTA VS EXPLICATIVA
Repeated K-fold
O repeated k-fold se resume a repetir o método k-fold várias vezes, com o objetivo de melhorar nossa reamostragem.
Código de exemplo
Vamos aplicar um método de treino 3 vezes em 10 folds. Para isso, utilizamos a função RepeatedStratifiedKFold(). Ela funciona semelhante ao StratifiedKFold(), porém com um argumento a mais: n_repeats, devemos inserir aqui o número de repetições que desejamos fazer.
repeatedKfSpam = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=11).split(XSpam, YSpam)
print(len(list(repeatedKfSpam)))30Repare que o tamanho da lista gerada é justamente o número de folds vezes o número de repetições, nesse caso 30.
Observações:
- a lista treino e teste de cada fold K são complementares
- a união entre lista treino e teste de cada fold K é tem como resultado os índices da base original.
- índices na lista de teste podem se repetir em outras listas de teste
- todos os índices passam n_repeats vezes pelo conjunto teste de algum k-fold
- os índices para treino se repetem (K-1) * n_repeats vezes em diferentes k-folds
Comparando Repeated K-fold com K-fold tradicional:
Uma vantagem do repeated k-fold em relação ao k-fold é que ele permite que um elemento na lista passe mais de uma vez pelo conjunto teste, o número inserido em n_repeats.
Uma limitação do repeated k-fold em relação ao k-fold é que, até o dia 04/06/2025, a implementação no scikitlearn, a função RepeatedStratifiedKFold(), não possui o argumento shuffle que o StratifiedKFold() possui. Ele por dentro roda a função StratifiedKFold() com o argumento shuffle em True, logo, se por alguma razão quisermos os dados não embaralhados, não devemos usar essa função e criar uma função como essa manualmente ou usar outro método de reamostragem.
Bootstrap
O bootstrap é uma técnica de reamostragem com o propósito de reduzir desvios e realizar amostragem dos dados de treino com repetições. Consiste em realizar amostragens com reposição a partir da amostra original. Quando fazemos amostragem com reposição, estamos recolocando o valor após cada amostra. Cada amostra, portanto, é independente do valor que veio antes dela.
Quando fazemos amostragem sem reposição, não estamos recolocando os valores, uma vez que um valor é selecionado, ele não pode ser selecionado novamente, portanto não geram resultados independetes já que o valor obtido em uma amostra afeta a possibilidade dos valores da próxima amostra. Dessa forma podemos escolher um tamanho de amostras maior ou menor do que o vetor de entrada.
Um ponto negativo do Bootstrap é que ao realizar um Bootstrap com menos amostras que o conjunto de dados original, a estratificação pode ficar um pouco diferente que a original, que para um número pequeno de amostras pode ser relevante.
Código de exemplo
O scikitlearn possui uma implementação do Bootstrap quando usamos a função resample com replace = True. Segue abaixo um exemplo de uso:
BootstrapSpam = resample(XSpam, YSpam, n_samples= 10000, random_state=11, replace=True, stratify=YSpam)- Primeiro argumento posicional recebe as variáveis explicativas, nesse caso, XSpam
- Segundo argumento posicional recebe a variável resposta, nesse caso, YSpam
n_samplesrecebe o número de amostras que queremos.random_staterecebe a semente de aleatoriedade.replacese True, permitirá reposição de amostras, se False, não. É essa variável em True que implementa o método Bootstrap. Se False e n_samples maior que número de amostras originais, um erro será gerado.stratifyrecebe a variável resposta ou None. Se for None, não será feito estratificação e portanto, não haverá garantia da manutenção da proporção da variável resposta.
A função gerou um vetor com dois vetores dentro: array(variaveisExplicativas, variavelResposta) para utilizarmos posteriormente. Repare que a função resample() automáticamente faz o embaralhamento dos dados.
print(BootstrapSpam[1])260 spam
2562 nonspam
3228 nonspam
3233 nonspam
1994 nonspam
...
326 spam
2193 nonspam
3188 nonspam
254 spam
428 spam
Name: type, Length: 10000, dtype: objectComo Spam possui um número muito alto de amostras e o embaralhemnto é sempre feito, visualizar o Bootstrap pode não ser tão fácil. Para facilitar o entendimento, vamos usar um exemplo mais simples: supomos que temos 10 indivíduos, numerados de 1 a 10. Ao realizar 3 bootstraps do mesmo tamanho da amostra obtemos:
B1 = [1, 1, 1, 2, 4, 6, 6, 7, 8, 10]
B2 = [1, 1, 2, 2, 3, 5, 7, 7, 8, 9]
B3 = [3, 4, 4, 5, 6, 6, 6, 8, 8, 8]