Este é um dos conceitos mais fundamentais com os quais lidamos na aprendizagem de máquina e previsão. Temos dois tipos de erros amostrais: o erro dentro da amostra (in sample error) e o erro fora da amostra (out of sample error).
Erro dentro da Amostra (In Sample Error)
A taxa de erro dentro da amostra refere-se ao erro calculado no mesmo conjunto de dados utilizado para treinar o modelo preditivo. Na literatura, isso é frequentemente denominado como “erro de resubstituição”. Em outras palavras, essa taxa de erro mede o quanto algoritmo de previsão se ajusta exatamente aos mesmos dados utilizados para o treinamento do modelo. No entanto, quando o modelo é aplicado a um novo conjunto de dados, é esperado que essa precisão diminua.
Erro fora da Amostra (Out of Sample Error)
É a taxa de erro que você recebe em um novo conjunto de dados. Na literatura às vezes é chamado de erro de generalização. Uma vez que coletamos uma amostra de dados e construímos um modelo para ela, podemos querer testá-lo em uma nova amostra, por exemplo uma amostra coletada em um horário diferente ou em um local diferente. Daí podemos analisar o quão bem o algoritmo executará a predição nesse novo conjunto de dados.
Algumas ideias-chave
Quase sempre o erro fora da amostra é o que interessa.
Erro dentro da amostra é menor que o erro fora da amostra.
Um erro frequente é ajustar muito o algoritmo aos dados que temos. Em outras palavras, criar um modelo sobreajustado (também chamado de overfitting(*)).
(*) Overfitting é um termo usado na estatística para descrever quando um modelo estatístico se ajusta muito bem a um conjunto de dados anteriormente observado e, como consequência, se mostra ineficaz para prever novos resultados.
Vejamos um exemplo de erro dentro da amostra vs erro fora da amostra:
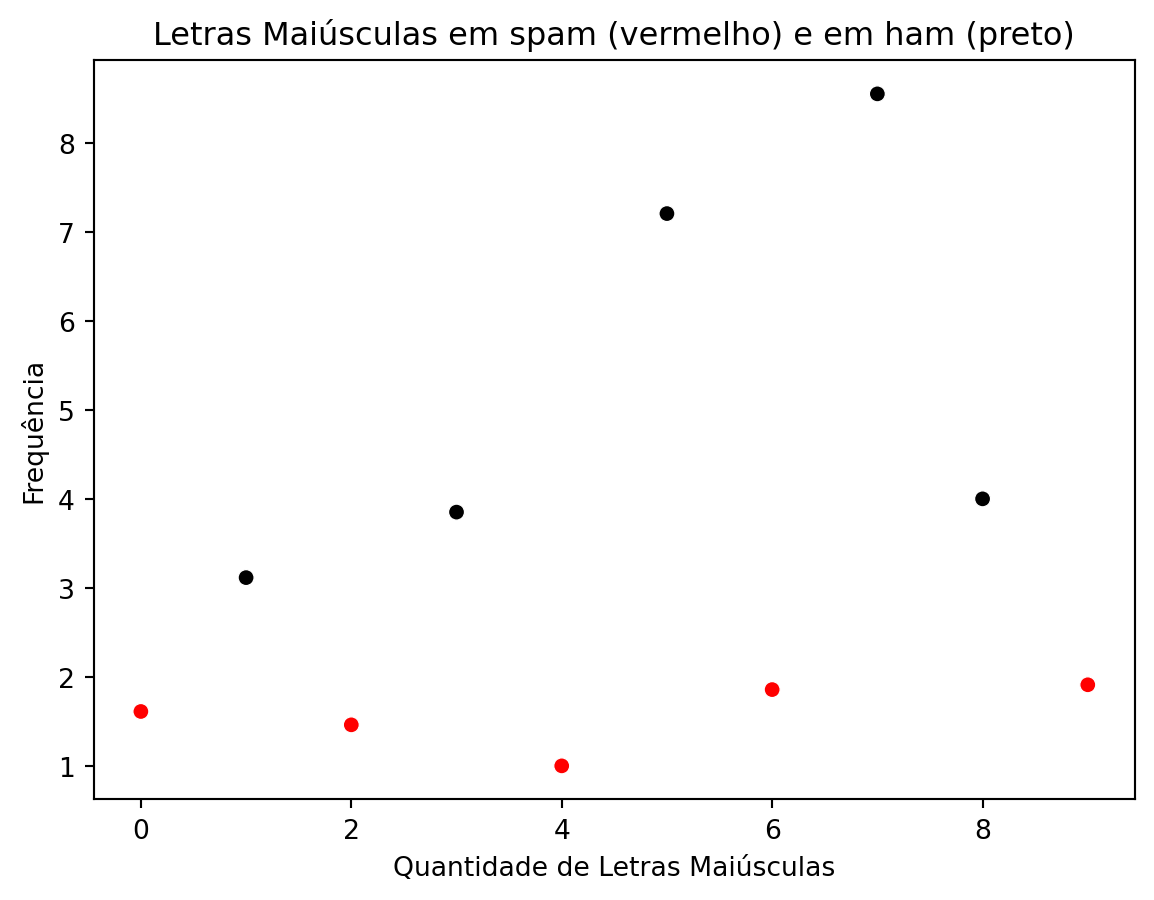
from sklearn.utils import resamplefrom sklearn.metrics import confusion_matriximport matplotlib.pyplot as pltimport seaborn as snsimport pandas as pdimport numpy as np# Seed# importando a base utilizando o pacote pandasspam = pd.read_csv("Cadernos Grupo Python\\Criação e Avaliação de Preditores\\spam.csv")spam["type_code"] = np.where(spam["type"] =="spam", 1, 0)# vamos selecionar um amostra de tamanho dez da basenp.random.seed(151)amostra_spam = resample(spam, n_samples=10, replace=False)# criando gráfico de dispersão para a média de letras maiúsculascores = ['red', 'black']sns.scatterplot(x=range(len(amostra_spam['capitalAve'])), y=amostra_spam['capitalAve'], c=[cores[label] for label in amostra_spam['type_code']])plt.title('Letras Maiúsculas em spam (vermelho) e em ham (preto)')plt.xlabel('Quantidade de Letras Maiúsculas')plt.ylabel('Frequência')plt.show()# 322
Podemos notar que, em geral, as mensagens classificadas como spam possuem uma frequência maior de letras maiúsculas do que as mensagens classificadas como não spam. Com base nisso queremos construir um preditor, onde podemos classificar e-mails como spam se a frequência de letras maiúsculas for maior que uma determida constante, e não spam caso contrário.
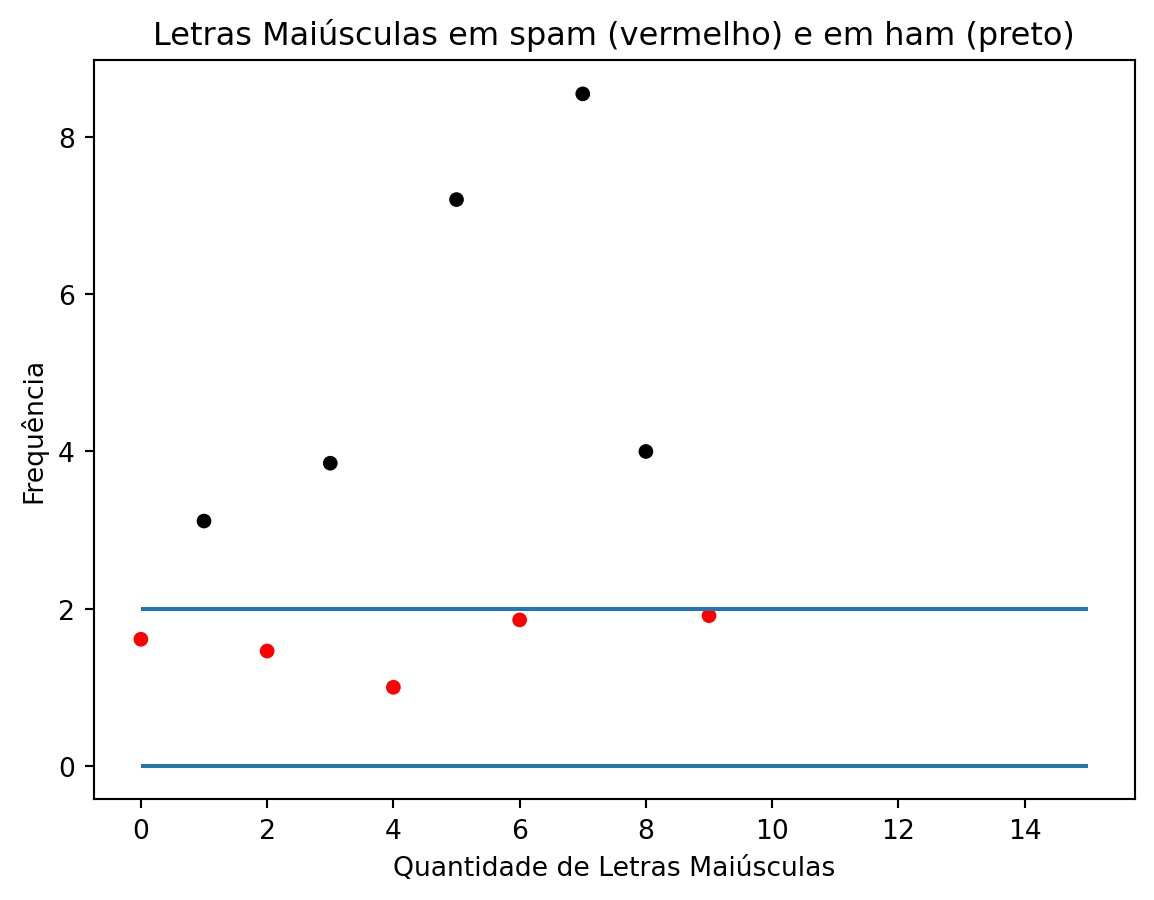
Veja que se separarmos os dados pela frequência de letras maiúsculas maior que 2,5 e classificarmos o que está acima como spam e abaixo como não spam, ainda teríamos duas observações que não são spam acima da linha.
# Criando um gráfico de dispersão para a média de letras maiúsculascores = ['red', 'black']sns.scatterplot(x=range(len(amostra_spam['capitalAve'])), y=amostra_spam['capitalAve'], c=[cores[label] for label in amostra_spam['type_code']])plt.hlines(y = [0, 2], xmin=[0,0], xmax=[15, 15])plt.title('Letras Maiúsculas em spam (vermelho) e em ham (preto)')plt.xlabel('Quantidade de Letras Maiúsculas')plt.ylabel('Frequência')plt.show()
Note que obtivemos uma precisão perfeita nessa amostra, como já era esperado. Nesse caso, o erro dentro da amostra é de 0%. Mas será que esse modelo é o mais eficiente em outros dados também?
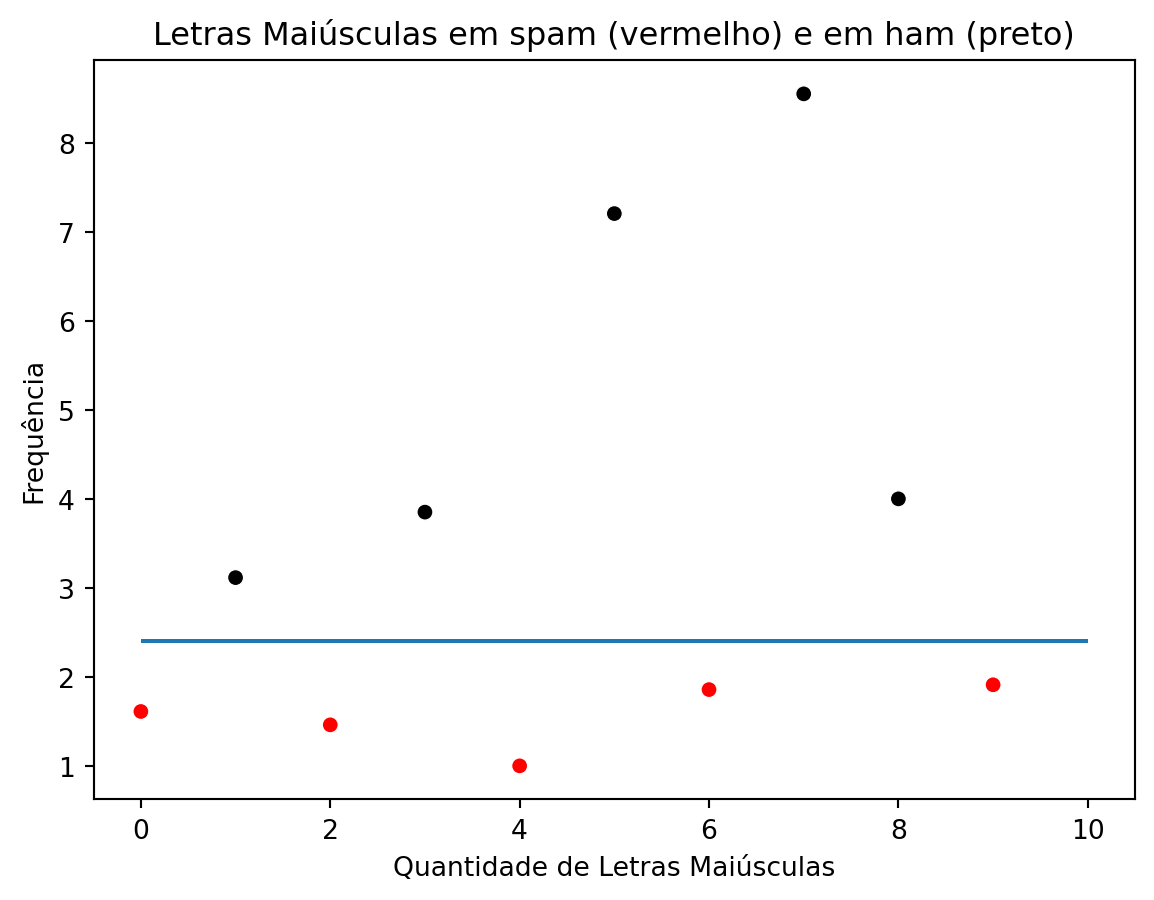
Vamos usar essa segunda regra para criarmos um modelo mais geral:
letras maiúsculas > 2,4 ⇒ spam;
letras maiúsculas <= 2,4 ⇒ não spam.
cores = ['red', 'black']sns.scatterplot(x=range(len(amostra_spam['capitalAve'])), y=amostra_spam['capitalAve'], c=[cores[label] for label in amostra_spam['type_code']])plt.hlines(y = [2.4], xmin=[0], xmax=[10])plt.title('Letras Maiúsculas em spam (vermelho) e em ham (preto)')plt.xlabel('Quantidade de Letras Maiúsculas')plt.ylabel('Frequência')plt.show()
Observe que utilizando o modelo sobreajustado obtivemos um erro fora da amostra de 40,77%, enquanto que com o modelo geral esse erro foi de 27,95%. Note que se queremos construir um modelo que melhor representa qualquer amostra que pegarmos, um modelo não sobreajustado possuirá uma precisão maior.