4 Design de predição
1. Defina sua taxa de erro (benchmark).
Por hora iremos utilizar uma taxa de erro genérica, mas em um próximo iremos falar sobre quais são as diferentes taxas de erro possíveis que você pode escolher.
Por exemplo, podemos calcular o chamado erro majoritário que é o limite máximo abaixo do qual o erro de um classificador deve estar. Ele é dado por 1−p, onde p é a proporção da categoria mais recorrente na variável de interesse. Por exemplo, se a variável de interesse possui 2 categorias: A e B. Se 85% dos dados estão rotulados na categoria A e 15% na categoria B, entao temos que a categoria A é a classe majoritária e 100%−85%=15% é o erro majoritário.
Caso o erro do preditor seja superior ao erro majoritário, seria melhor classificar toda nova amostra na classe majoritária, certo? Depende.
Digamos que um psicólogo quer construir um classificador para prever se uma pessoa tem ou não ideação suicida, ou seja, pensa ou planeja suicídio. Suponha que ele tem uma base de dados com 1000 observações cuja variável de interesse “Tem ideação suicida?” está rotulada com “sim” ou “não” e 97% das observações, no caso indivíduos/pacientes, não possuem tal característica e portanto 3% dos indivíduos possuem. Criado o preditor, observamos que o erro é de 5%, assim como mostrado a seguir:
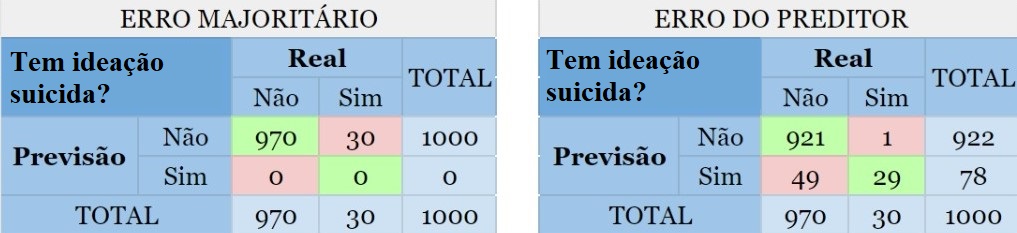
As partes em vermelho mostram o erro cometido por ambos os métodos. Agora note as pessoas que possuem ideação suicída porém foram classficadas como não possuidoras dessa característica. Quanto isso afetará no dignóstico do psicólogo?
2. Divida os dados em Treino e Teste, ou Treino, Teste e Validação (opcional).
Como já comentado, o conjunto de treino deve ser criado para construir seu modelo e o conjunto de testes para avaliar seu modelo. Fazemos isso com o intuito de criarmos um modelo que se ajuste bem a qualquer base de dados, e não apenas à nossa. É comum usar 70% da amostra como treino e 30% como teste, mas isso não é uma regra. Podemos também repartir os dados em treino, teste e validação(*). É importante ficar claro que quem está conduzindo as análises é quem fica encarregado de decidir o que fica melhor para cada amostra.
3. Definimos quais variáveis serão utilizadas para estimação dos parâmetros do classificador/regressor (função preditora).
Nem sempre utilizar todas as variáveis do banco de dados é importante para o modelo. Pode acontecer de termos variáveis que não ajudam na predição, como por exemplo aquelas com uma variância quase zero (frequência muito alta de um único valor). Iremos estudar algumas formas de selecionar as melhores variáveis para o modelo em breve.
4. Definimos o método que será utilizado para construção do classificador/regressor.
Isso poderá ser feito, por exemplo, utilizando o método de validação cruzada (cross-validation), que será explicado detalhadamente em um capítulo mais à frente.
5. Obtenção do melhor modelo.
Utilizando a amostra TREINO, definimos os parâmetros da função preditora (classificador/regressor), obtendo o modelo final.
6. Aplicamos o modelo final na amostra TESTE (uma única vez), para estimar o erro do preditor.
Aplicamos o modelo final obtido na amostra de teste apenas uma vez. Se aplicarmos várias vezes até encontrar o melhor modelo, estaremos, de certa forma, utilizando a amostra de teste para treinar o modelo, o que influenciaria o ajuste do modelo com base nos resultados do teste. Isso não é desejável, pois o objetivo da amostra de teste é servir como uma “nova amostra” para estimar a taxa de erro do modelo.
(*) Opcionalmente poderá ser criado um conjunto de validação, com o intuito de servir como um “pré-teste”, que também será usado para avaliar seu modelo. Quando repartimos o conjunto de dados dessa forma, utilizamos o treino para construir o modelo, avaliamos o modelo na validação (ou seja, o ajuste do modelo é influenciado por ela), e se o resultado não for bom, retornamos ao treino para ajustar um outro modelo. Então novamente testamos o modelo na validação, e assim sucessivamente até acharmos um modelo que se adequou bem tanto ao treino quanto à validação. Aí, finalmente, aplicamos ele ao conjunto teste, avaliando na prática a sua qualidade.