Antes de criarmos um modelo de predição, é importante plotarmos as variáveis do nosso modelo antecipadamente para observarmos se há algum comportamento estranho entre elas. Por exemplo, podemos ter uma variável que assuma frequentemente um único valor (possui muito pouca variabilidade), o que não acrescenta informações relevantes ao modelo, ou uma que possua alguns dados faltantes (NA’s). O que podemos fazer nesses casos, que é o que iremos estudar neste capítulo, é realizar alterações em tais variáveis, afim de melhorar/otimizar a nossa predição/classificação. Essa é a ideia de pré-processar.
9.1 Padronizando os dados
Vamos carregar o banco de dados spam e criar amostras treino e teste.
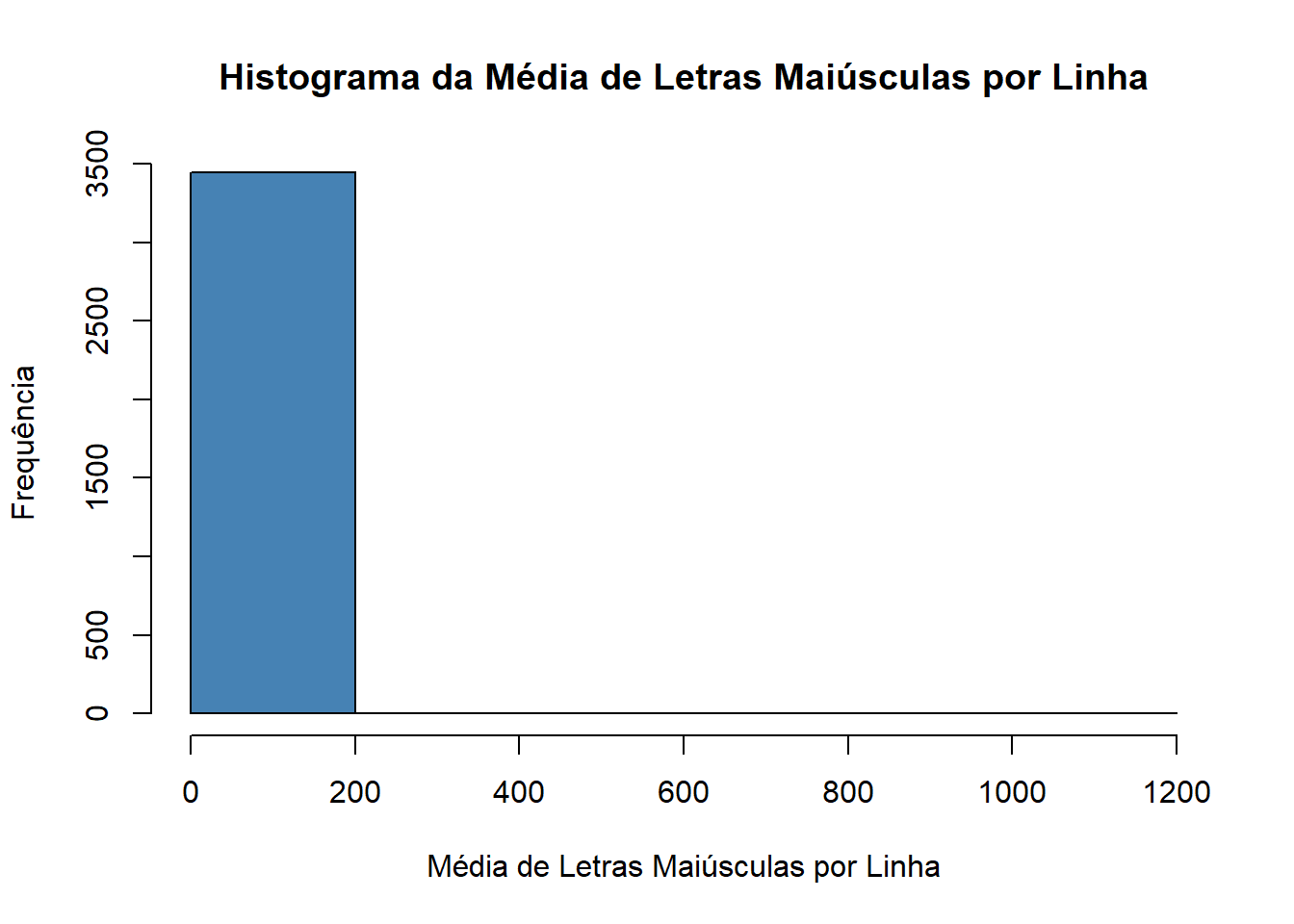
library(kernlab)library(caret)data(spam)set.seed(123)noTreino =createDataPartition(y = spam$type, p =0.75, list = F)treino = spam[noTreino,]teste = spam[-noTreino,]# Vamos olhar para a variável capitalAve (média de letras maiúsculas por linha):hist(treino$capitalAve,ylab ="Frequência",xlab ="Média de Letras Maiúsculas por Linha",main ="Histograma da Média de Letras Maiúsculas por Linha",col="steelblue", breaks =4)
Podemos notar que muitos elementos estão próximos do 0 e os outros estão muito espalhados. Ou seja, essa variável não está trazendo muita informação para o modelo.
mean(treino$capitalAve)
[1] 4.863991
sd(treino$capitalAve)
[1] 27.80173
Podemos ver que a média é pequena mas o desvio padrão é muito grande.
Para que os algoritmos de machine learning não sejam enganados pelo fato de a variável ser altamente variável, vamos realizar um pré-processamento. Vamos padronizar os dados da variável pela amostra treino pegando cada valor dela e subtraindo pela sua média e dividindo pelo seu desvio padrão.
treinoCapAve = treino$capitalAve# Padronizando a variável:treinoCapAveP = (treino$capitalAve-mean(treinoCapAve))/sd(treinoCapAve)# Média da variável padronizada:mean(treinoCapAveP)
[1] 9.854945e-18
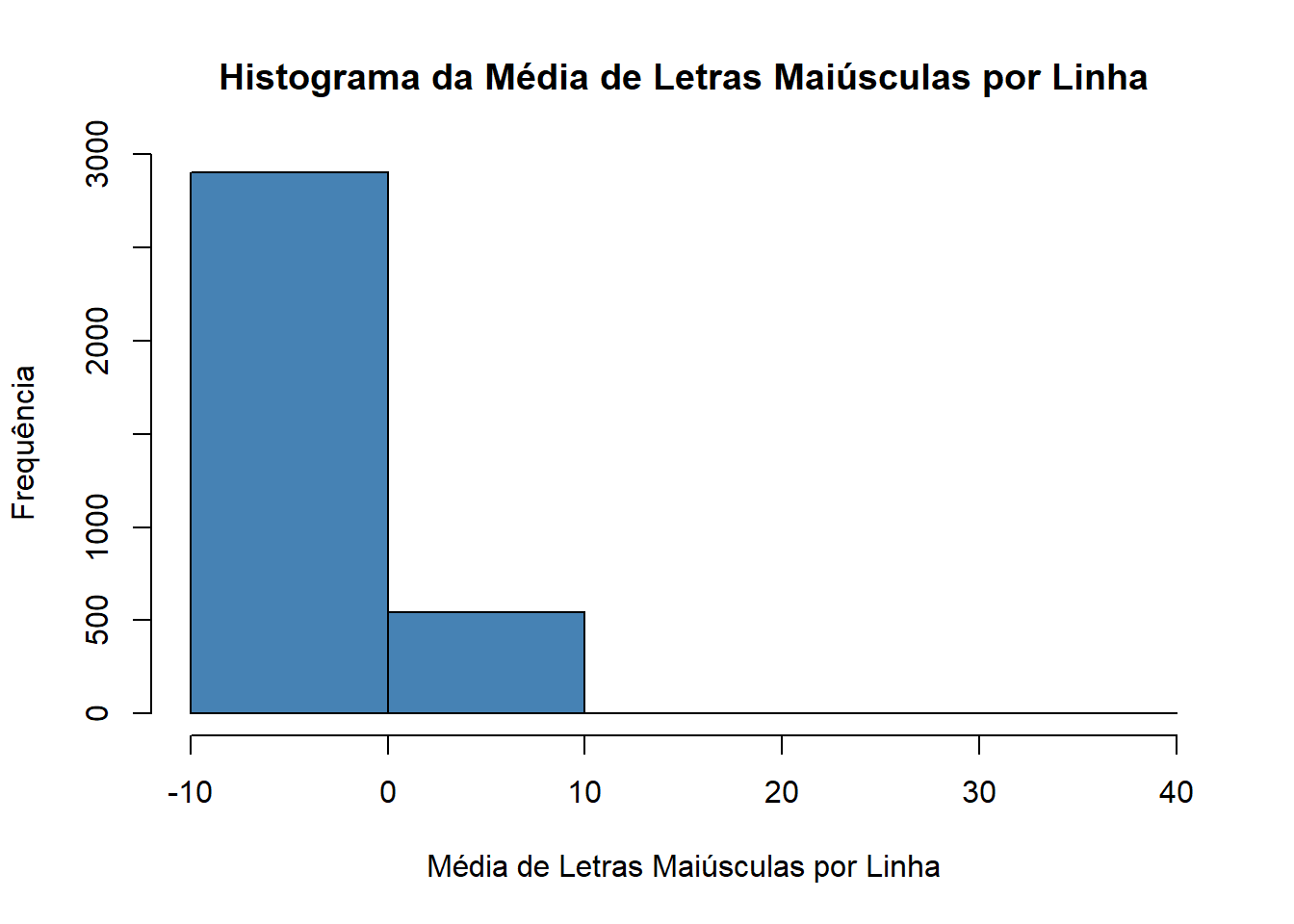
Agora temos média 0.
# Desvio padrão da variável padronizada:sd(treinoCapAveP)
[1] 1
E variância 1.
# Vamos olhar para a variável capitalAve (média de letras maiúsculas por linha):hist(treinoCapAveP, ylab ="Frequência", xlab ="Média de Letras Maiúsculas por Linha",main ="Histograma da Média de Letras Maiúsculas por Linha",col="steelblue", breaks =4)
Agora vamos aplicar a mesma transformação na amostra teste. Uma coisa a ter em mente é que ao aplicar um algoritmo no conjunto de teste, só podemos usar os parâmetros que estimamos no conjunto de treino. Ou seja, temos que usar a média e o desvio padrão da variável capitalAve do TREINO.
testeCapAve = teste$capitalAve# Aplicando a transformação:testeCapAveP = (testeCapAve-mean(treinoCapAve))/sd(treinoCapAve)# Média da variável transformada do conjunto teste:mean(testeCapAveP)
[1] 0.04713308
# Desvio Padrão da variável transformada do conjunto teste:sd(testeCapAveP)
[1] 1.486708
Nesse caso não obtemos média 0 e variância 1, afinal nós utilizamos os parâmetros do treino para a padronização. Mas podemos notar que os valores estão relativamente próximos disso.
9.2 Padronizando os dados com a função PreProcess()
Podemos realizar o pré-processamento utilizando a função preProcess() do caret. Ela realiza vários tipos de padronizações, mas para utilizarmos a mesma (subtrair a média e dividir pelo desvio padrão) utilizamos o método c(“center”,“scale”).
padronizacao =preProcess(treino, method =c("center","scale"))# O comando acima cria um modelo de padronização. Para ter efeito ele deve ser aplicado nos dados com o# comando predict().treinoCapAveS =predict(padronizacao,treino)$capitalAve# Média da variável padronizada:mean(treinoCapAveS)
[1] 8.680584e-18
# Desvio padrão da variável padronizada:sd(treinoCapAveS)
[1] 1
Note que chegamos à mesma média e variância de quando padronizamos sem o preProcess().
Agora vamos aplicar essa padronização no conjunto de teste:
testeCapAveS =predict(padronizacao,teste)$capitalAve# Note que aplicamos o modelo de padronização criado com a amostra treino.
Observe que também encontramos o mesmo valor da média e desvio padrão de quando padronizamos a variável do conjunto teste anteriormente (sem o preProcess()):
mean(testeCapAveS)
[1] 0.04713308
sd(testeCapAveS)
[1] 1.486708
Repare que também chegamos à mesma média e variância de quando padronizamos sem o preProcess().
9.3 preProcess como argumento da função train()
Também podemos utilizar o preProcess dentro da função train da seguinte forma:
modelo =train(type~., data = treino, preProcess =c("center","scale"), method ="glm")
A única limitação é que esse método aplica a padronização em todas as variáveis numéricas.
Obs.: Quando for padronizar uma variável da sua base para depois treinar seu algoritmo, lembre-se que colocar a variável padronizada de volta na sua base.
9.4 Tratando NA’s
É muito comum encontrar alguns dados faltantes (NA’s) em uma base de dados. E quando você usa essa base para fazer predições, o algoritmo preditor muitas vezes falha, pois eles são criados para não manipular dados ausentes (na maioria dos casos). O mais recomendado a se fazer é descartar esses dados, principalmente se o número de variáveis for muito pequeno. Porém, em alguns casos, podemos tentar substituir os NA’s da amostra por dados de outros elementos que possuam características parecidas.
Obs: Este é um procedimento que deve ser feito com muito cuidado, apenas em situações de real necessidade.
9.5 Método k-Nearest Neighbors (knn)
O método k-Nearest Neighbors (knn) consiste em procurar os k vizinhos mais próximos do elemento que possui o dado faltante de uma variável de interesse, calculando a média dos valores observados dessa variável dos k vizinhos e imputando esse valor ao elemento.
Vamos utilizar novamente a variável capitalAve do banco de dados spam como exemplo.
library(kernlab)library(caret)data(spam)set.seed(13343)# Criando amostras treino e teste:noTreino =createDataPartition(y = spam$type, p =0.75, list = F)treino = spam[noTreino,]teste = spam[-noTreino,]
Originalmente, a variável capitalAve não possui NA’s. Mas para o objetivo de compreendermos como esse método funciona, vamos inserir alguns valores NA’s.
NAs =rbinom(dim(treino)[1], size =1, p =0.05)==1
O que fizemos com a função rbinom() é criar uma amostra de tamanho “dim(treino)[1]” (quantidade de elementos no treino) de uma variável Bernoulli com probabilidade de sucesso = 0,05. Ou seja, o vetor NAs será um vetor do tipo logical, onde será TRUE se o elemento gerado pela rbinom() é “1” (probabilidade de 0,05 de acontecer) e FALSE se é “0” (probabilidade 0,95 de acontecer).
Para preservar os valores originais, vamos criar uma nova coluna de dados no treino chamada capAve, que será uma réplica da variável capitalAve, mas com os NA’s inseridos em alguns valores.
library(dplyr)# Criando a nova variável capAve com os mesmos valores da capitalAve:treino = treino %>%mutate(capAve = capitalAve)# Inserindo os Na's:treino$capAve[NAs] =NA
Então, recapitulando: criamos manualmente uma base de dados que possui valores faltantes. Agora podemos aplicar o método KNN para imputar valores aos NA’s, escolhendo essa opção por meio do argumento “method” da função preProcess(). Na vida real, obviamente, não vamos criar dados faltantes, mas é possível que nossas bases tenham esses NA’s e vamos ter que preenchê-los de alguma forma. O padrão da função é utilizar k=5 (número de vizinhos mais próximos igual a cinco).
imput =preProcess(treino, method ="knnImpute")# Aplicando o modelo de pré-processamento ao banco de dados treino:treino$capAve =predict(imput,treino)$capAve# Olhando para a variável capAve após o pré-processamento:head(treino$capAve, n =20)
Note que além de ter imputado valores aos NA’s, o comando knnImpute também padronizou os dados.
Obs: O método knnImpute só resolve os NA’s quando os dados faltantes são NUMÉRICOS.
E se quiséssemos aplicar o método de imputar valores aos NA’s em todo o conjunto de dados, e não só em apenas 1 variável? Também podemos fazer isso utilizando a função preProcess().
Vamos utilizar a base de dados “airquality”, já disponível no R, como exemplo.
Note que essa base possui alguns valores NA’s em algumas variáveis.
# Realizando o método KNN para imputar valores aos NA's:imput =preProcess(base, method ="knnImpute")# Aplicando o modelo em toda a base de dados:nova_base =predict(imput, base)# Vamos olhar para a nova base:head(nova_base, n =15)
Note que ela não possui mais NA’s e todas as variáveis foram padronizadas.
9.6 Utilizando Algoritmos de Machine Learning com o Pacote mlr
O pacote mlr fornece vários métodos de imputação para dados faltantes. Alguns desses métodos possuem técnicas padrões como, por exemplo, imputação por uma constante (uma constante fixa, a média, a mediana ou a moda) ou números aleatórios (da distribuição empírica dos dados em consideração ou de uma determinada família de distribuições). Para mais informações sobre como utilizar essas imputações padrões, consulte https://mlr.mlr-org.com/reference/imputations.html.
Entretanto, a principal vantagem desse pacote - que é o que abordaremos nessa seção - é a possibilidade de imputação dos valores faltantes de uma variável por meio de predições de um algoritmo de machine learning, utilizando como base as outras variáveis. Ou seja, além de aceitar valores faltantes de variáveis numéricas para a imputação, ele também aceita de variáveis categóricas.
Podemos observar todos os algoritmos de machine learning possíveis de serem utilizados nesse pacote através da função listLearners().
Para um problema de imputação de NA’s de variáveis numéricas temos os seguintes métodos:
Vamos utilizar o banco de dados “heart” para realizarmos a imputação de dados faltantes categóricos.
library(caret)library(readr)library(dplyr)heart =read_csv("Heart.csv")# Verificando se a base "heart" possui valores NA's em alguma variável:apply(heart, 2, function(x) any(is.na(x)))
X1 Age Sex ChestPain RestBP Chol
FALSE FALSE FALSE FALSE FALSE FALSE
Fbs RestECG MaxHR ExAng Oldpeak Slope
FALSE FALSE FALSE FALSE FALSE FALSE
Ca Thal HeartDisease
FALSE FALSE FALSE
Note que a base não possui dados faltantes. Para fins didáticos, vamos inserir alguns na variável “Thal”.
# Criando um novo banco de dados que possuirá NA's:new.heart =as.data.frame(heart)set.seed(133)# Criando um vetor do tipo *logical*, onde será TRUE se o elemento gerado pela rbinom() é "1"# (probabilidade de 0,1 de acontecer):NAs =rbinom(dim(new.heart)[1], size =1, p =0.1)==1# Inserindo os NA's na variável Thal:new.heart$Thal[NAs] =NAnew.heart$Thal
Agora vamos imputar categorias aos dados faltantes da variável Thal. Iremos fazer isso através da função impute(). O único problema é que possuímos variáveis do tipo character na base de dados, e a função não aceita esta classe nos dados.
Agora vamos imputar os dados no conjunto treino com a função impute().
Para isso passamos como argumento:
A base de dados que possui os valores faltantes;
A variável resposta do modelo, ou seja, a variável de interesse para predição. No nosso exemplo essa variável é a “HeartDisease”, que indica se uma pessoa possui uma doença cardíaca;
Lista contendo o método de imputação para cada coluna do banco de dados. Como apenas temos NA’s na variável “Thal”, a lista só possuirá essa variável, seguida do método de imputação que desejamos para ela. Vamos utilizar o método de árvores de decisão (“rpart”).
Essa função retorna uma lista de tamanho 2, onde primeiro se encontra a base de dados após a imputação dos valores e em seguida detalhes do método utilizado.
Vamos olhar para a variável após a imputação dos dados:
treino$data[,"Thal"]
[1] normal normal normal normal normal normal
[7] reversable reversable fixed normal fixed reversable
[13] normal normal normal reversable reversable reversable
[19] normal normal normal normal reversable normal
[25] normal reversable reversable reversable normal reversable
[31] reversable normal reversable normal normal normal
[37] normal reversable normal normal reversable reversable
[43] reversable reversable normal normal reversable normal
[49] reversable reversable reversable normal normal reversable
[55] reversable fixed reversable normal reversable normal
[61] normal reversable normal normal normal reversable
[67] normal normal normal normal normal reversable
[73] reversable normal reversable reversable reversable normal
[79] normal normal reversable reversable reversable reversable
[85] reversable reversable fixed normal reversable reversable
[91] normal reversable normal normal reversable reversable
[97] normal normal normal normal normal reversable
[103] reversable normal reversable normal normal reversable
[109] normal normal normal reversable reversable normal
[115] normal reversable reversable normal normal normal
[121] reversable reversable normal reversable reversable normal
[127] normal reversable reversable fixed normal normal
[133] reversable reversable reversable normal normal fixed
[139] reversable reversable normal reversable normal normal
[145] normal normal normal normal reversable reversable
[151] reversable reversable reversable reversable normal normal
[157] reversable reversable normal normal normal normal
[163] normal reversable normal normal normal normal
[169] normal normal normal normal normal normal
[175] normal reversable reversable normal normal normal
[181] normal normal reversable reversable normal fixed
[187] reversable normal normal normal normal normal
[193] reversable normal normal normal fixed fixed
[199] reversable normal reversable fixed reversable normal
[205] reversable normal normal normal normal reversable
[211] normal reversable reversable fixed fixed reversable
[217] normal normal fixed reversable normal normal
[223] normal
Levels: fixed normal reversable
Para implementarmos esse algoritmo no conjunto de dados teste basta utilizarmos a função reimpute() que implementaremos o mesmo método com os mesmos critérios criados no conjuno treino. Basta passar os seguintes argumentos:
A base de dados que possui os valores faltantes;
O mesmo método utilizado no treino.
A função retorna a base de dados com os valores imputados.
teste =reimpute(teste, treino$desc)teste$Thal
[1] fixed reversable reversable reversable normal normal
[7] normal reversable normal normal fixed normal
[13] normal reversable normal normal normal reversable
[19] normal normal normal normal normal reversable
[25] normal reversable reversable fixed normal reversable
[31] reversable normal reversable reversable normal normal
[37] reversable reversable normal reversable reversable reversable
[43] reversable normal normal fixed normal reversable
[49] normal normal normal normal normal reversable
[55] normal normal normal normal normal normal
[61] normal normal reversable normal normal normal
[67] normal normal reversable normal fixed reversable
[73] reversable reversable
Levels: fixed normal reversable
9.7 Variável Dummy
As variáveis dummies ou variáveis indicadoras são formas de agregar informações qualitativas em modelos estatísticos. Ela atribui 1 se o elemento possui determinada característica, ou 0 caso ele não possua. Esse tipo de transformação é importante para modelos de regressão pois ela torna possível trabalhar com variáveis qualitativas.
Vamos utilizar o banco de dados Wage, do pacote ISLR. Este banco possui informações sobre 3000 trabalhadores do sexo masculino de uma região dos EUA, como por exemplo idade (age), tipo de trabalho (jobclass), salário (wage), entre outras. Nosso objetivo é tentar prever o salário do indivíduo em função das outras variáveis.
library(ISLR)data(Wage)head(Wage)
year age maritl race education region
231655 2006 18 1. Never Married 1. White 1. < HS Grad 2. Middle Atlantic
86582 2004 24 1. Never Married 1. White 4. College Grad 2. Middle Atlantic
161300 2003 45 2. Married 1. White 3. Some College 2. Middle Atlantic
155159 2003 43 2. Married 3. Asian 4. College Grad 2. Middle Atlantic
11443 2005 50 4. Divorced 1. White 2. HS Grad 2. Middle Atlantic
376662 2008 54 2. Married 1. White 4. College Grad 2. Middle Atlantic
jobclass health health_ins logwage wage
231655 1. Industrial 1. <=Good 2. No 4.318063 75.04315
86582 2. Information 2. >=Very Good 2. No 4.255273 70.47602
161300 1. Industrial 1. <=Good 1. Yes 4.875061 130.98218
155159 2. Information 2. >=Very Good 1. Yes 5.041393 154.68529
11443 2. Information 1. <=Good 1. Yes 4.318063 75.04315
376662 2. Information 2. >=Very Good 1. Yes 4.845098 127.11574
Vamos olhar para 2 variáveis: jobclass (tipo de trabalho) e health_ins (indica se o trabalhador possui plano de saúde).
library(ggplot2)Wage %>%ggplot(aes(x=jobclass)) +geom_bar(aes(fill=jobclass)) +ylab("Frequência") +guides(fill=F) +theme_light() +ggtitle("Gráfico de Barras para o Tipo de Trabalho")
Wage %>%ggplot(aes(x=health_ins)) +geom_bar(aes(fill=health_ins)) +ylab("Frequência") +guides(fill=F) +theme_light() +ggtitle("Gráfico de Barras para o Plano de Saúde")
Vamos transformar essas 2 variáveis em dummies por meio da função dummyVars().
dummies =dummyVars(wage~jobclass+health_ins, data = Wage)# Aplicando ao modelo:Dummies =predict(dummies, newdata = Wage)head(Dummies)
Note que ele transforma cada categoria numa variável dummy. Ou seja, como temos 2 categorias para jobclass, cada uma delas vira uma variável dummy, cujos nomes são “jobclass.1 Industrial” e “jobclass.2 Information”. Então se para um indivíduo temos um “1” na categoria “jobclass=industrial”, isso implica que terá um “0” na categoria “jobclass=information”, pois ou o indivíduo tem um tipo de trabalho, ou tem outro. O mesmo vale para as categorias de plano de saúde.
Vale frisar que se separamos nossa base de dados em Treino e Teste, usar essa técnica de dummyVars vai criar as dummies considerando somente as classes que estão presentes na base de treino. Se na base de teste existirem outras classes possíveis que não estão presentes na base de treino, essas classes precisam ser especificadas na variável da base de treino com a função “factor”. Assim, o algoritmo vai saber que essa classe também precisa de uma variável dummy.
Observe também que esse novo modelo criado é uma matriz:
class(Dummies)
[1] "matrix" "array"
Vamos anexar esse novo objeto aos dados:
Wage_dummy =cbind(Wage, Dummies)head(Wage_dummy)
year age maritl race education region
231655 2006 18 1. Never Married 1. White 1. < HS Grad 2. Middle Atlantic
86582 2004 24 1. Never Married 1. White 4. College Grad 2. Middle Atlantic
161300 2003 45 2. Married 1. White 3. Some College 2. Middle Atlantic
155159 2003 43 2. Married 3. Asian 4. College Grad 2. Middle Atlantic
11443 2005 50 4. Divorced 1. White 2. HS Grad 2. Middle Atlantic
376662 2008 54 2. Married 1. White 4. College Grad 2. Middle Atlantic
jobclass health health_ins logwage wage
231655 1. Industrial 1. <=Good 2. No 4.318063 75.04315
86582 2. Information 2. >=Very Good 2. No 4.255273 70.47602
161300 1. Industrial 1. <=Good 1. Yes 4.875061 130.98218
155159 2. Information 2. >=Very Good 1. Yes 5.041393 154.68529
11443 2. Information 1. <=Good 1. Yes 4.318063 75.04315
376662 2. Information 2. >=Very Good 1. Yes 4.845098 127.11574
jobclass.1. Industrial jobclass.2. Information health_ins.1. Yes
231655 1 0 0
86582 0 1 0
161300 1 0 1
155159 0 1 1
11443 0 1 1
376662 0 1 1
health_ins.2. No
231655 1
86582 1
161300 0
155159 0
11443 0
376662 0
# Removendo as variáveis categóricas do banco de dados completo (opcional):Wage_dummy = dplyr::select(Wage_dummy, -c(jobclass,health_ins))head(Wage_dummy)
year age maritl race education region
231655 2006 18 1. Never Married 1. White 1. < HS Grad 2. Middle Atlantic
86582 2004 24 1. Never Married 1. White 4. College Grad 2. Middle Atlantic
161300 2003 45 2. Married 1. White 3. Some College 2. Middle Atlantic
155159 2003 43 2. Married 3. Asian 4. College Grad 2. Middle Atlantic
11443 2005 50 4. Divorced 1. White 2. HS Grad 2. Middle Atlantic
376662 2008 54 2. Married 1. White 4. College Grad 2. Middle Atlantic
health logwage wage jobclass.1. Industrial
231655 1. <=Good 4.318063 75.04315 1
86582 2. >=Very Good 4.255273 70.47602 0
161300 1. <=Good 4.875061 130.98218 1
155159 2. >=Very Good 5.041393 154.68529 0
11443 1. <=Good 4.318063 75.04315 0
376662 2. >=Very Good 4.845098 127.11574 0
jobclass.2. Information health_ins.1. Yes health_ins.2. No
231655 0 0 1
86582 1 0 1
161300 0 1 0
155159 1 1 0
11443 1 1 0
376662 1 1 0
Como comentado acima, nós temos uma variável dummy para cada categoria. Como tínhamos 2 variáveis qualitativas, então ficamos com 4 variáveis dummies. Porém, para um modelo de regressão, isso não é necessário. Estaríamos inserindo 2 variáveis com colinearidade perfeita no modelo: jobclass=industrial é totalmente correlacionada com jobclass=information, pois o resultado de uma influencia totalmente o da outra (o mesmo vale para as variáveis do plano de saúde). Dessa forma, vamos remover essas variáveis desnecessárias.
year age maritl race education region
231655 2006 18 1. Never Married 1. White 1. < HS Grad 2. Middle Atlantic
86582 2004 24 1. Never Married 1. White 4. College Grad 2. Middle Atlantic
161300 2003 45 2. Married 1. White 3. Some College 2. Middle Atlantic
155159 2003 43 2. Married 3. Asian 4. College Grad 2. Middle Atlantic
11443 2005 50 4. Divorced 1. White 2. HS Grad 2. Middle Atlantic
376662 2008 54 2. Married 1. White 4. College Grad 2. Middle Atlantic
health logwage wage jobclass.1. Industrial
231655 1. <=Good 4.318063 75.04315 1
86582 2. >=Very Good 4.255273 70.47602 0
161300 1. <=Good 4.875061 130.98218 1
155159 2. >=Very Good 5.041393 154.68529 0
11443 1. <=Good 4.318063 75.04315 0
376662 2. >=Very Good 4.845098 127.11574 0
health_ins.1. Yes
231655 0
86582 0
161300 1
155159 1
11443 1
376662 1
Uma maneira mais simples de fazer isso, sem precisarmos retirar cada variável “na mão”, é utilizar o argumento “fullRank=T” da função dummyVars().
dummies =dummyVars(wage~jobclass+health_ins, data = Wage, fullRank = T)# Aplicando ao modelo:Dummies =predict(dummies, newdata = Wage)
Note que o comando fullRank=T removeu a primeira variável de cada classificação.
# Anexando esse novo objeto aos dados:Wage_dummy =cbind(Wage, Dummies)head(Wage_dummy)
year age maritl race education region
231655 2006 18 1. Never Married 1. White 1. < HS Grad 2. Middle Atlantic
86582 2004 24 1. Never Married 1. White 4. College Grad 2. Middle Atlantic
161300 2003 45 2. Married 1. White 3. Some College 2. Middle Atlantic
155159 2003 43 2. Married 3. Asian 4. College Grad 2. Middle Atlantic
11443 2005 50 4. Divorced 1. White 2. HS Grad 2. Middle Atlantic
376662 2008 54 2. Married 1. White 4. College Grad 2. Middle Atlantic
jobclass health health_ins logwage wage
231655 1. Industrial 1. <=Good 2. No 4.318063 75.04315
86582 2. Information 2. >=Very Good 2. No 4.255273 70.47602
161300 1. Industrial 1. <=Good 1. Yes 4.875061 130.98218
155159 2. Information 2. >=Very Good 1. Yes 5.041393 154.68529
11443 2. Information 1. <=Good 1. Yes 4.318063 75.04315
376662 2. Information 2. >=Very Good 1. Yes 4.845098 127.11574
jobclass.2. Information health_ins.2. No
231655 0 1
86582 1 1
161300 0 0
155159 1 0
11443 1 0
376662 1 0
9.8 Variância Zero ou Quase-Zero
Algumas vezes em um conjunto de dados podemos ter uma variável que assuma somente um único valor para todos os indivíduos, ou seja, ela possui variância zero. Ou podemos ter uma com uma frequência muito alta de um único valor, possuindo, assim, variância quase zero. Essas variáveis não auxiliam na predição, pois possuem o mesmo valor em muitos indivíduos, trazendo, assim, pouca informação ao modelo. Nosso objetivo é, então, identificar essas variáveis, chamadas de near zero covariates, para que possamos removê-las do nosso modelo de predição.
Para detectar as near zero covariates, utilizamos a função nearZeroVar() do pacote caret. Vamos verificar se há near zero covariates no banco de dados “forestfires”.
Na função nearZeroVar() passamos primeiro a base de dados a ser analisada, depois o argumento lógico “saveMetrics”, o qual se for “TRUE” retorna todos os detalhes sobre as variáveis da base de dados afim de identificar as near zero covariates. A saída da função fica da seguinte forma:
Note que é retornado uma tabela onde nas linhas se encontram as variáveis da base de dados e as colunas podemos resumir da seguinte forma:
1ª coluna: a Taxa de Frequência de cada variável. Essa taxa é calculada pela razão de frequências do valor mais comum sobre o segundo valor mais comum.
2ª coluna: a Porcentagem de Valores Únicos. Ela é calculada utilizando o número de valores distintos sobre o número de amostras.
3ª coluna: indica se a variável tem variância zero.
4ª coluna: indica se a variável tem variância quase zero.
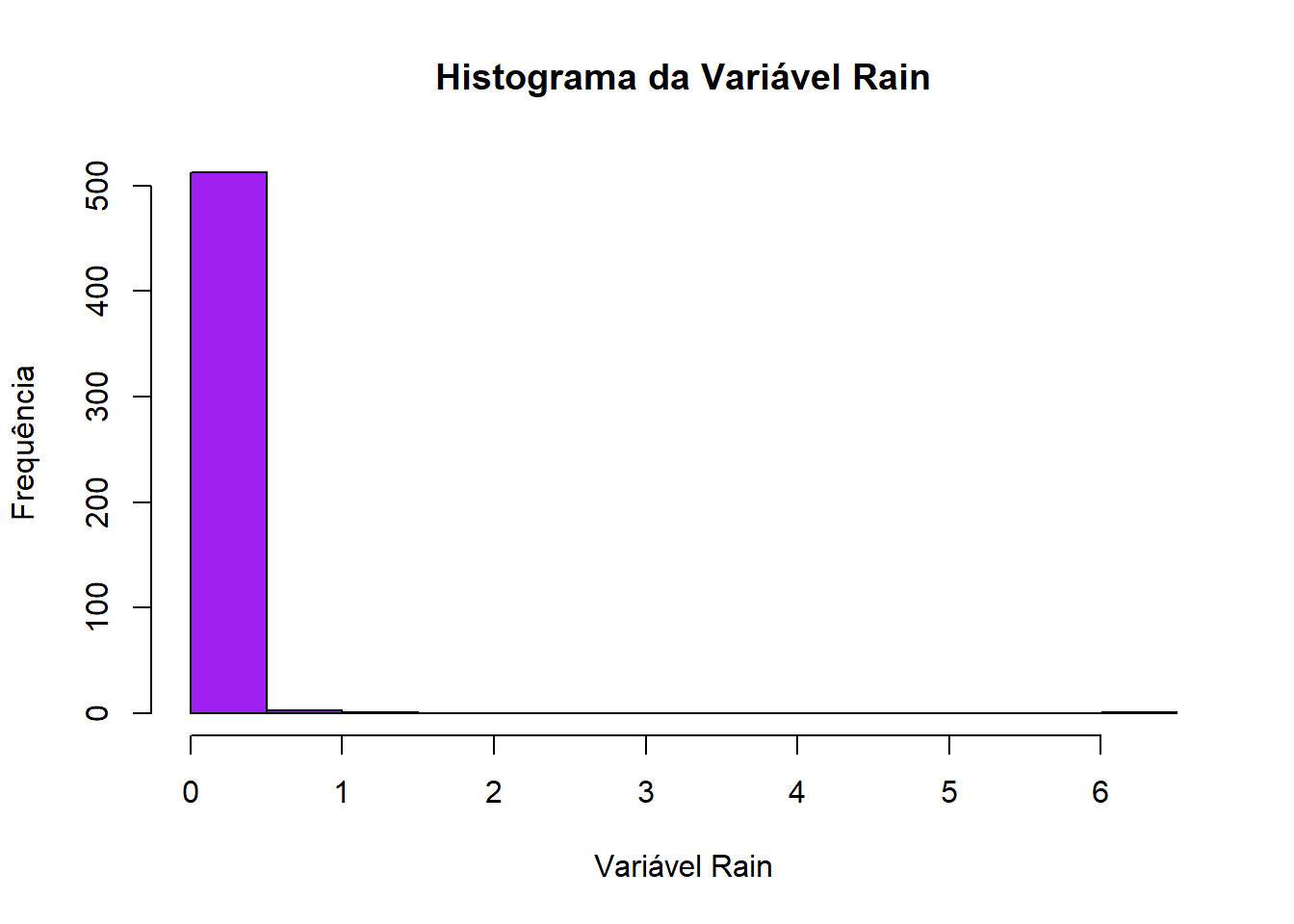
Podemos observar que a variável “rain” possui variância quase zero, portanto ela é uma near zero covariate.
hist(incendio$rain, main ="Histograma da Variável Rain",xlab ="Variável Rain", ylab ="Frequência", col ="purple")
Logo, vamos excluir ela da nossa base de dados. O argumento “saveMetrics=FALSE” (default da função) retorna justamente qual(is) variável(is) do bando de dados é(são) near zero covariate .
# A tibble: 6 × 12
X Y month day FFMC DMC DC ISI temp RH wind area
<dbl> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 7 5 mar fri 86.2 26.2 94.3 5.1 8.2 51 6.7 0
2 7 4 oct tue 90.6 35.4 669. 6.7 18 33 0.9 0
3 7 4 oct sat 90.6 43.7 687. 6.7 14.6 33 1.3 0
4 8 6 mar fri 91.7 33.3 77.5 9 8.3 97 4 0
5 8 6 mar sun 89.3 51.3 102. 9.6 11.4 99 1.8 0
6 8 6 aug sun 92.3 85.3 488 14.7 22.2 29 5.4 0
9.9 Análise de Componentes Principais (PCA)
Muitas vezes podemos ter variáveis em excesso no nosso banco de dados, o que torna difícil a manipulação das mesmas. A ideia geral do PCA (Principal Components Analysis) é reduzir a quantidade de variáveis, obtendo combinações interpretáveis delas. O PCA faz isso tranformando um conjunto de observações de variáveis possivelmente correlacionadas num conjunto de valores de variáveis linearmente não correlacionadas, chamadas de componentes principais. Isso é feito utilizando os autovalores e autovetores da matriz de covariâncias da base de dados. O número de componentes principais é, inicialmente, sempre igual ao número de variáveis originais - mas, por conta de suas propriedades matemáticas, é possível selecionar uma quantidade de Componentes Principais muito menor do que a quantidade de variáveis originais da base de dados, enquanto se mantém a mesma (ou muito próximo da mesma) variabilidade original do conjunto de dados.
Efetivamente, se reduz drasticamente a complexidade da base de dados, enquanto se mantém a variabilidade original (não se perde informação).
Para utilizarmos o PCA no nosso modelo, basta colocar o argumento preProcess=“pca” na função train(). Por padrão, são selecionadas componentes que expliquem 95% da variabilidade do conjunto de dados.
Vamos aplicar o método “glm”, com a opção “pca”, no banco de dados spam.
set.seed(887)modelo = caret::train(type ~ ., method ="glm", preProcess ="pca", data = treino)# Aplicando o modelo na amostra TESTE:testePCA =predict(modelo, teste)
Avaliando nosso modelo com a matriz de confusão:
confusionMatrix(teste$type, testePCA)
Confusion Matrix and Statistics
Reference
Prediction nonspam spam
nonspam 653 44
spam 56 397
Accuracy : 0.913
95% CI : (0.8952, 0.9287)
No Information Rate : 0.6165
P-Value [Acc > NIR] : <2e-16
Kappa : 0.817
Mcnemar's Test P-Value : 0.2713
Sensitivity : 0.9210
Specificity : 0.9002
Pos Pred Value : 0.9369
Neg Pred Value : 0.8764
Prevalence : 0.6165
Detection Rate : 0.5678
Detection Prevalence : 0.6061
Balanced Accuracy : 0.9106
'Positive' Class : nonspam
O modelo obteve uma acurácia de 0,93, o que pode-se considerar uma alta taxa de acerto.
É possível alterar a porcentagem de variância a ser explicada pelos componentes nas opções do train().
Por exemplo, vamos alterar a porcentagem da variância para 60%.
controle =trainControl(preProcOptions =list(thresh =0.6))# Treinando o modelo 2:set.seed(754)modelo2 = caret::train(type ~ ., method ="glm", preProcess ="pca", data = treino, trControl = controle)# Aplicando o modelo 2:testePCA2 =predict(modelo2, teste)
Avaliando o segundo modelo pela matriz de confusão:
confusionMatrix(teste$type,testePCA2)
Confusion Matrix and Statistics
Reference
Prediction nonspam spam
nonspam 647 50
spam 71 382
Accuracy : 0.8948
95% CI : (0.8756, 0.9119)
No Information Rate : 0.6243
P-Value [Acc > NIR] : < 2e-16
Kappa : 0.7778
Mcnemar's Test P-Value : 0.06904
Sensitivity : 0.9011
Specificity : 0.8843
Pos Pred Value : 0.9283
Neg Pred Value : 0.8433
Prevalence : 0.6243
Detection Rate : 0.5626
Detection Prevalence : 0.6061
Balanced Accuracy : 0.8927
'Positive' Class : nonspam
Obtemos uma acurácia de 0,92, o que indica também uma alta taxa de acerto, porém um pouco menor que a do modelo anterior. Note que a sensitividade e a especificidade também diminuíram.
Em geral, são utilizados pontos de corte para a variãncia explicada acima de 0,9.
9.10PCA fora da função train()
Podemos também realizar o pré-processamento fora da função train(). Primeiramente vamos criar o pré-processamento, utilizando a amostra treino.
Por último, aplicamos o modelo criado com a amostra treino na amostra teste pré-processada.
testeMod =predict(modelo, testePCA)# Avaliando o modelo:confusionMatrix(testePCA$type, testeMod)
Confusion Matrix and Statistics
Reference
Prediction nonspam spam
nonspam 653 44
spam 56 397
Accuracy : 0.913
95% CI : (0.8952, 0.9287)
No Information Rate : 0.6165
P-Value [Acc > NIR] : <2e-16
Kappa : 0.817
Mcnemar's Test P-Value : 0.2713
Sensitivity : 0.9210
Specificity : 0.9002
Pos Pred Value : 0.9369
Neg Pred Value : 0.8764
Prevalence : 0.6165
Detection Rate : 0.5678
Detection Prevalence : 0.6061
Balanced Accuracy : 0.9106
'Positive' Class : nonspam
9.11 Normalização dos Dados
Normalização de dados consiste em reescalar as variáveis (por exemplo, para um intervalo entre [0, 1] ou padronizando com média zero e desvio padrão unitário). Essa técnica pode reduzir o custo computacional e a complexidade do modelo. Fazer isso traz uma série de propriedades vantajosas quando estamos usando modelos estatísticos, e também para modelos de Aprendizado de Máquinas. Essas propriedades vantajosas se resumem em reduzir custo computacional (pois os números ficam pequenos), reduzir a complexidade dos modelos (pois a simetria conquistada na normalização requer menos parâmetros ou parâmetros menos profundos).
9.11.1 Transformação de Box-Cox
A transformação de Box-Cox é uma transformação feita nos dados (contínuos) para tentar normalizá-los. Considerando \(X_1, X_2, ..., X_n\) as variáveis do conjunto de dados original, essa transformação consiste em encontrar um \(\lambda\) tal que as variáveis transformadas \(Y_1, Y_2, ..., Y_n\) se aproximem de uma distribuição normal com variância constante.
Essa transformação é dada pela seguinte forma: \(Y_i = \frac{X_i^\lambda-1}{\lambda}\), se \(\lambda \neq 0\). O parâmetro \(\lambda\) é estimado utilizando o método de máxima verossimilhança.
O método de Box-Cox é o método mais simples e o mais eficiente computacionalmente. Podemos aplicar a transformação de Box-Cox nos dados através da função preProcess().
Obs: a transformação de Box-Cox só pode ser utilizada com dados positivos.
A transformação de Box-Cox é, por exemplo, muito utilizado no contexto de modelos de Séries Temporais quando a escala da variável resposta é muito grande (muito grande aqui seria já na escala de milhares). A aplicação da transformação é conhecida na literatura por melhorar muito os modelos de Análise de Séries Temporais.
treinoBC =preProcess(treino, method ="BoxCox")
9.11.2 Outras Transformações
9.11.2.1 Transformação de Yeo-Johnson
A transformação de Yeo-Johnson é semelhante à transformação de Box-Cox, porém ela aceita preditores com dados nulos e/ou dados negativos. Também podemos aplicá-la aos dados através da função preProcess().
O método exponencial de Manly também consiste em estimar um \(\lambda\) tal que as variáveis transformadas se aproximem de uma distribuição normal. Assim como a transformação de Yeo-Johnson, ela também aceita dados positivos, nulos e negativos. Essa transformação é dada pela seguinte forma: